XML-Parser Grundlegendes
XML-Parser lassen sich nach zwei Kriterien unterscheiden. Das erste ist, ob sie validieren oder nicht, und das zweite, welche Schnittstelle sie zum Zugriff auf das XML-Dokument anbieten (SAX oder DOM). Beide Parser-Pakete bieten die vier möglichen Varianten an (validierender und nicht validierender SAX-Parser, validierender und nicht validierender DOM-Parser).
Die meisten von euch haben wahrscheinlich nur die Hälfte von dem verstanden, was ich eben geschrieben habe, aber das macht nichts, denn im Folgenden kommt nun eine etwas eingehendere Beschreibung.
Das erste Kriterium, also validierend oder nicht validierend, ist schnell erklärt, deshalb gibts dafür kein extra Kapitel. Wenn ihr den XML-Teil dieser Seite studiert habt, und das solltet ihr bevor ihr euch mit den Parsern beschäftigt, müßte euch das eigentlich auch schon klar sein. Ein validierender Parser überprüft, ob das XML-Dokument das er parst valide ist, also den Regeln einer DTD folgt. Es ist also zwingend eine DTD erforderlich. Außerdem wird die Wohlgeformtheit des Dokuments getestet.
Ein nicht validierender Parser überprüft nur, ob das XML-Dokument der XML-Spezifikation folgt, also wohlgeformt ist. In diesem Fall ist also keine DTD nötig, es schadet aber auch nicht wenn eine vorhanden ist.
Da das Validieren eines Dokumentes durch den Parser jedoch sehr zeitaufwändig ist, sollte man wann immer möglich darauf verzichten. Das ist zum Beispiel der Fall, wenn man anderweitig sicherstellen kann, daß das Dokument valide ist.
Soviel zum ersten Kriterium nach denen sich Parser unterscheiden lassen. Das zweite war die Schnittstelle über die der Zugriff auf das Dokument erfolgt. Es gibt derer zwei, nämlich DOM und SAX. Beide werde ich nun näher erläutern.
SAX
SAX heißt Simple API for XML, und wurde von den Mitgliedern der XML-DEV Mailing List entwickelt. Am 11. Mai 1998 wurde die Version 1.0 veröffentlicht.
SAX ist "event based". Das bedeutet, daß der Parser, wenn er ein bestimmtes XML-Konstrukt (beispielsweise ein Element, ein Kommentar oder eine Processing Instruction) liest, ein Ereignis auslöst. Auch bei Fehlern oder Warnungen löst der Parser ein Ereignis aus. Diese Ereignisse können vom Entwickler ganz individuell behandelt werden, indem man einen eigenen Eventhandler schreibt, und diesen beim Parser registriert. So kann die Applikation je nach Anforderung auf das XML-Dokument reagieren. Nach dem Behandeln eines Ereignisses ist dieses allerdings "weg", sofern ihr euch nicht selbst um eine Speicherung der Ereignisse bemüht.
Folgendes Beispiel mag eurem Verständnis helfen: Nehmen wir an, wir haben ein XML-Dokument, in dem dieser Abschnitt vorkommt:
<zitat>
Drum prüfe wer sich ewig bindet, ob sich nicht was Besseres findet.
</zitat>
Der Parser würde beim Lesen folgende Ereignisse auslösen:
- öffnendes Tag
- Text
- schließendes Tag
Wenn nun ein Ereignis auftritt, wird der entsprechende Eventhandler aufgerufen. Dies ist eine Methode, die der Entwickler (also ihr) selber schreiben kann. Man könnte dann beispielsweise den Text (also das eigentliche Zitat) auf dem Bildschirm ausgeben.
DOM
DOM heißt Document Object Model, und ist ein Standard des W3C (momentan in der Version 1.0). Beim DOM wird beim Parsen des XML-Dokuments ein Baum aufgebaut, der DOM-Tree. Das Root-Element des XML-Dokuments fungiert als Wurzel für den DOM-Tree. Dieser Baum steht dann im Speicher zur Verfügung. Er ist quasi das Abbild des XML-Dokuments.
<buch>
<titel>Galgenlieder</titel>
<autor>
<vorname>Christian</vorname>
<name>Morgenstern</name>
</autor>
</buch>
Obiges XML-Dokument würde einen DOM-Parser veranlassen folgenden DOM-Tree aufzubauen:
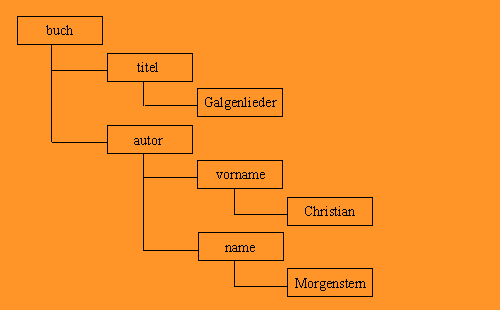
Die DOM-API bietet Werkzeuge zum Zugriff auf den Baum, und zum Verändern des Baums, und ist deshalb ideal für interaktive Anwendungen geeignet (das gesamte Object Model steht die ganze Zeit im Speicher zur Verfügung). Allerdings ist DOM aufwendiger (sprich langsamer) und benötigt mehr Speicher als SAX.
DOM versus SAX
SAX ist schnell und einfach, hat allerdings den großen Nachteil, daß kein Object Model zur Verfügung steht, auf das ihr nach dem Parsen zugreifen könnt. SAX ist ideal für alle Anwendungen, die das XML-Dokument nur einmal "durchlesen" sollen, beispielsweise um es anzuzeigen.
DOM hingegen ist bedeutend langsamer, bietet aber die Möglichkeit der einfachen Manipulation des DOM-Trees (also des XML-Dokuments). DOM solltet ihr also bei Anwendungen verwenden, die interaktiv auf das XML-Dokument zugreifen müssen (Editoren zum Beispiel) oder die das Dokument mehrfach brauchen (es steht ja als DOM-Tree immer im Speicher zur Verfügung).
![]()
![]()
![]()